🐜(6/30)
動的計画法,解答見てあ〜ってなることしか出来なくて萎える.
動的計画法01
重量と価値が$w_i,v_i$である$N$個の荷物を,重量の総和が$W$を超えないように選んでナップサックに詰め込んだとき,価値の総和の最大値を出力せよ.
手法1
メモ化再帰
memsetによる初期化
手法2
- 漸化式からの直接DP(再帰不使用)
メモ化再帰を利用する
$\text{dp}[i][j]$を$i$番目以降の品物を重量が$j$以下になるようにナップサックに詰め込んだときの価値総和の最大値を表す$2$次元配列とすると,
 取り出さない状態と取り出して価値を比べた状態で
最大の方を選んでいけば良い.呼び出す際は
取り出さない状態と取り出して価値を比べた状態で
最大の方を選んでいけば良い.呼び出す際はrec(0,W)で再帰的に探索させてやれば良い.
メモ化再帰を用いないと再帰の深度が高くなり,計算量は $O(2^{n})$ となるが,メモ化を用いることで $O(NW)$まで減らすことができる.
int dp[1001][1001]; int rec(int i, int j) { if (dp[i][j] >= 0) return dp[i][j]; int res; if (i == N) return res = 0; else if (j < w[i]) return res = rec(i + 1, j); else res = max(rec(i + 1, j), rec(i + 1, j - w[i]) + v[i]); return dp[i][j] = res; } int main() { cin >> N >> W; memset(dp, -1, sizeof(dp)); REP(i, N) { cin >> w[i]; } REP(i, N) { cin >> v[i]; } cout << rec(0, W) << endl; return 0; }
漸化式を用いる
上記の漸化式の他,以下のように考えることが可能である.
今度は$\text{dp}[i+1][j]$を$i$番目までの品物から重量が$j$以下になるようにナップサックに詰め込んだときの価値総和の最大値を表す$2$次元配列とすると,

となる.漸化式を立てることができればforを用いて単純に以下のように実装することも可能.
計算量は見ての通り$O(NW)$で済む.
int dynamic() { memset(dp, 0, sizeof(dp)); for (int i = 0; i < N; i++) { for (int j = 0; j <= W; j++) { if (w[i] > j) { dp[i + 1][j] = dp[i][j]; } else { dp[i + 1][j] = max(dp[i][j], dp[i][j - w[i]] + v[i]); } } } return dp[N][W]; }
動的計画法02
重量と価値が$w_i,v_i$である$N$個の荷物を,重量の総和が$W$を超えないように選んでナップサックに詰め込んだとき,価値の総和の最大値を出力せよ.ただし,同一の荷物を複数詰め込んでも良い.
$\text{dp}[i+1][j]$を計算するに当たっては,荷物$i$を$k$個選んだうちの価値最大を格納すれば良いので,ナイーブに実装するなれば, $$ \text{dp}[i+1][j]\leftarrow\max(\text{dp}[i][j],{\text{dp}[i][j-kW[i]]+kV[i]|1\leq k}) $$ となるが,これでは計算量が$O(nW^{2})$となる.
ここでdpテーブルに着目してみると,$\text{dp}[i+1][j-W[i]]$にて,すでに荷物$~i~$を$k-~1$ 個選んだときの荷物の最大値が出ている.よって以下のようにすることで計算量を減らせる.
$$ \text{dp}[i+1][j]\leftarrow\max(\text{dp}[i][j],\text{dp}[i+1][j-W[i]]+V[i]) $$
(もちろん$j<W[i]$の場合分けを忘れずに!!)
int dp[1001][1001]; int N, W[1000], V[1000], w; int dynamic() { REP(i, N) { REP(j, w + 1) { if (j < W[i]) { dp[i + 1][j] = dp[i][j]; continue; } dp[i + 1][j] = max(dp[i][j], dp[i + 1][j - W[i]] + V[i]); } } return dp[N][w]; }
🐜本の進捗(6/25)
本棚の奥底にあった蟻本を取り出した.
![プログラミングコンテストチャレンジブック [第2版] ?問題解決のアルゴリズム活用力とコーディングテクニックを鍛える?](https://images-fe.ssl-images-amazon.com/images/I/41bHxtpurqL._SL160_.jpg "プログラミングコンテストチャレンジブック [第2版] ?問題解決のアルゴリズム活用力とコーディングテクニックを鍛える?")
プログラミングコンテストチャレンジブック [第2版] ?問題解決のアルゴリズム活用力とコーディングテクニックを鍛える?
- 作者: 秋葉拓哉,岩田陽一,北川宜稔
- 出版社/メーカー: マイナビ
- 発売日: 2012/01/28
- メディア: 単行本(ソフトカバー)
- 購入: 25人 クリック: 473回
- この商品を含むブログ (36件) を見る
テンプレート
#include <bits/stdc++.h> #define REP(i, n) for (int i = 0; i < n; i++) #define REP2(i, st, ed) for (int i = st; i <= ed; i++) using namespace std; static const int inf = 1 << 28; int main() { return 0; }
chaper 2
2-1 全探索問題
深さ優先探索01
部分和問題
数列${a_n}$から,要素をいくつか取り出して部分数列$b$を作る.入力$S$に対して,$b$の和が$S$となるような組み合わせは存在するか
アルゴリズム例
$i\leftarrow 0,s \leftarrow 0$
$dfs(index, sum):$
- $i=n$ならば終了
- 部分和に要素$a[i]$を...
- 含める$dfs(i+1,s+a[i])$
- 含めない$dfs(i+1,s)$
bool dfs(int i, int sum) { if (i == n) return sum == k; if (dfs(i + 1, sum)) return true; if (dfs(i + 1, sum + a[i])) return true; }
深さ優先n探索02
8近傍島数算出問題
大きさ$n\times m~$の庭があります.そこに雨が降り,水たまりが出来ました.ある水たまりに対し,8近傍に隣接した水たまりがある場合その水たまりは連結していると考えます.いくつの水たまりがあるかを出力せよ.
void dfs(int x, int y) { if (map[x][y] == 0 || x < 0 || y < 0 || x > n || y > m) return; map[x][y] = 0; REP2(i, -1, 1) { REP2(j, -1, 1) { dfs(x - i, y - j); } } }
幅優先探索01
迷路探索
$n\times m~$の迷路に対し,最短経路でスタートからゴールに到達したときのステップ数を出力せよ.入力は
.を通路,#を壁,Sを開始地点,Gをゴール地点とする.
距離をd=infでリセット
$d(all)=\infty$
始点をd=0にして,キューに積む
$d(start)=0$
$Q.push(start)$
キューのつづく限り以下の処理をする
キューの先頭を取り出す
$current = Q.pop()$
ゴールならば抜ける
次の未探索かつ壁でない経路候補全てに以下の処理をする
キューに積む
d を更新する
$d(next) \leftarrow d(current) + 1$
typedef pair<int, int> V; int dx[4] = {-1, 0, 0, 1}; int dy[4] = {0, -1, 1, 0}; int bfs() { queue<V> que; REP(i, n) { REP(j, m) { d[i][j] = INF; } } que.push(V(stx, sty)); d[stx][sty] = 0; while (!que.empty()) { V cur = que.front(); que.pop(); if (cur.first == gox && cur.second == goy) break; REP(i, 4) { int nx = cur.first + dx[i]; int ny = cur.second + dy[i]; if (0 <= nx && nx < n && 0 <= ny && ny < m && mp[nx][ny] != '#' && d[nx][ny] == INF) { que.push(V(nx, ny)); d[nx][ny] = d[cur.first][cur.second] + 1; } } } return d[gox][goy]; }
2-2 貪欲法
貪欲法01
区間スケジューリング問題.
現在時間から選べるスケジュールのうち,最も早い時間に終わる ものを選択すると良い.
void greedy() { sort(_pair, _pair + n); int ans = 0, t = 0; REP(i, n) { if (t < _pair[i].second) { ans++; t = _pair[i].first; } } cout << ans << endl; }
貪欲法02
実践例:
$n$個の点が数直線状にあり,その座標は$X_i,(i=1,2,...,n)$である.その点のうちいくつかを選び印をつけるとする.印をつけた点から$r$の範囲内にすべての点$X_i$を含めるためには,最低いくつの点に印をつける必要があるか
直感的な発想を実装すればOK
void greedy() { sort(p, p + n); int i = 0, ans = 0; while (i < n) { int s = p[i++]; while (i < n && p[i] <= s + r) i++; int m = p[i - 1]; while (i < n && p[i] <= m + r) i++; ans++; } cout << ans << endl; }
貪欲法03
辞書順最小
$n$文字からなる文字列$S$の先頭または末端から取り出して,末端に連結してできる$n$文字の文字列$T$を考える.$T$のうち辞書順で最小となるものを出力せよ.
基本,先頭と末端の辞書順を比べる. 先頭と末端が同じ文字だった場合に,次に続く(先頭+1と末端-1)文字同士を比較して,辞書順で小さかった方の端の文字を出力すれば良い.for文で実装できるが終了条件に注意する.
void greedy() { int a = 0, b = n - 1; bool left; while (a <= b) { for (int i = 0; a + i <= b; i++) { if (S[a + i] > S[b - i]) { left = false; break; } else if (S[a + i] < S[b - i]) { left = true; break; } } if (left) cout << S[a++]; else cout << S[b--]; } cout << endl; }
貪欲法04
木こりは木を切りたい.切りたい長さは$L_1,L_2,...,L_n$であり,もとの長さはちょうどこの長さの和に等しい.板を切るためには板の長さ分のコストが掛かるとする.たとえば長さ$21$の板を$13$と$8$に分割した際にかかるコストは$21$である.コストが最小で木を切り分けたときのかかるコストはいくらか
- $sum\leftarrow 0$
- $\text{while}~~L.length()\geq2$
- $\text{sort}(L, \leq)$
- $m_1 = L.front(),m_2=L.front()$
- $L.popFront()\times 2$
- $sum\leftarrow sum+m_1+m_2$
- $L.pushFront(m_1+m_2)$
- $\text{return}~~sum$
vector<int> L; void greedy() { int ans = 0; while (L.size() >= 2) { sort(L.rbegin(), L.rend()); int m1 = L.back(); L.pop_back(); int m2 = L.back(); L.pop_back(); ans += m1 + m2; L.push_back(m1 + m2); } cout << ans << endl; }
#4 Improved Techniques for Training GANs
https://arxiv.org/abs/1606.03498
要旨
半教師あり学習とリアリスティックな画像生成などのGANの応用に焦点を当ててアーキテクチャや訓練手順を提案する.
導入
GANは非凸ゲームのナッシュ均衡を多数のパラメータにより訓練し,求めることが必要. しかしながら,GANの学習には勾配降下が用いられ,ナッシュ均衡は使われていない.
GANの収束のための手法
Feature Matching
既存の直接,生成画像のディスクリミネータの評価関数を最大化させる手法のみではなく,ディスクリミネータの中間層の特徴量の期待値に一致させるようにジェネレータを訓練させる. 具体的には,${\bf f}({\bf \it{x}})$をディスクリミネータ中間層の活性化関数と定め,ジェネレータは次式で表される新しい評価関数を最小化させるように訓練する. $$||\mathbb{E}_{{\bf{\it x}}\sim p_{data}} {\bf f}({\bf{\it x}})- \mathbb{E}_{{\bf{\it z}}\sim {\it p}_{{\bf{\it z}}}} {\bf f}\left( {\it G}\left({\bf\it{z}}\right) \right)||_2^2 $$ 経験的に,GANが不安定になる状況下において,この手法が有効であることが示されている.
Minibatch Discrimination
モード崩壊の起こる状況下では,ディスクリミネータの勾配は多くの同様の点において,同一の方向を 指すことがある.ディスクリミネータは各々のサンプルを独立して処理するため, その勾配間の調整がなく,ジェネレータの出力がたがいにより似ないように指示する機構が存在しない. 勾配降下ではディスクリミネータが同一の画像をジェネレータから生成されることを学習するが学習過程において分離して考察することができない.
ミニバッチのサンプル間の近さをディスクリミネータに判別させることでこの問題を解決することができる.
そこで次のようなモデルを考える.${\bf f}(x_i) \in \mathbb R^A$をいま,ディスクリミネータの中間層にて生成される入力の特徴量のベクトルとする.このベクトルをテンソル$T\in \mathbb R^{A\times B\times C}$で掛け,行列$M_i\in\mathbb R^{B\times C}$を得たとする. この方法では,のL1距離をサンプルごとに取り,負号の指数乗を取る.すなわちサンプルに対して,距離関数を $$ c_b(x_i,x_j)=\exp\left(-||M_{i,b}-M_{j,b}||_1 \right)\in\mathbb R $$ と定める.次にサンプルのこのミニバッチ層の出力を以下のように定義する $$ \begin{eqnarray*} \displaystyle o(x_i)_b&=&\sum_{j=1}^nc_b(x_i,x_j)\in \mathbb R\\ \displaystyle o(x_i)&=&\left[ o(x_i)_1,o(x_i)_2, ... , o(x_i)_B\right]\in \mathbb R^B\\ \displaystyle o(X)&\in& \mathbb R^{n\times B} \end{eqnarray*} $$
このミニバッチ層の出力と,入力である中間層特徴量を連結させ,ディスクリミネータの次の層の入力に渡す.この層を適用することで,今までのようにディスクリミネータは各サンプルに対して,単一の数値を出力し訓練データか否かを示す機能を保ちつつ,側面的情報として, ニバッチ内の他のサンプルに関する情報を,ディスクリミネータに与えることが可能になる.
履歴平均
半教師あり学習
GANにおいて,ラベル数のラベルデータを用いて半教師あり学習を行う際は,ジェネレータから出力された画像を新たに,個めのクラスへと分類させるようにクラス分類器(=ディスクリミネータ)を 学習させてやればよいということが分かる.すなわち通常のGANにおける生成画像を看過するように学習する項と,このモデルにおけるは等価であるといえる.
を最大化させることで,ラベルの降られていないデータに対しても,それに対応する実データのクラスに分類されるの1つの画像でクラス分類を行うことが可能になる.
実データと生成データを半々に含むようなデータセットに対して,損失関数は次のように定義できる.
$$ \begin{eqnarray*} L&=&-\mathbb E_{x,y\sim p_{data}(x,y)}[\log p_{model}(y|x)] -\mathbb E_{x\sim G}[\log p_{model}(y=K+1|x)]\\ &=&L_{supervised}+L_{unsupervised} \text{where}\\ L_{supervised}&=&-\mathbb E_{x,y\sim p_{data}(x,y)}[\log p_{model}(y|x,y<K+1)]\\ L_{unsupervised}&=&-\{\mathbb E_{x\sim p_{data}(x)}[\log p_{model}(y=K+1|x)] +\mathbb E_{x\sim G}[\log p_{model}(y=K+1|x)]\}\\ \end{eqnarray*} $$ このように分解することでこの損失関数は教師有り項に対しては,標準的なクロスエントロピー最適化問題と解釈でき,教師無し項は,と定めることで, $$ L_{unsupervised}=-\{\mathbb E_{x\sim p_{data}(x)}\log D(x)+ \mathbb E_{z\sim noise}\log(1-D(G(z)))\} $$ となり,標準的なGANのディスクリミネータの損失関数に等しくなる.
実装上の観点では,もの出力を設ける必要がないことが言える.ソフトマックス層の出力は,各々の出力に対してのように任意関数の差分をとっても出力値に変化がないという特性を考慮すると,ディスクリミネータを と定めることで,仮想的にと等価になる.
ワンショット学習を行う際には,どのデータに対して,正解ラベルを与えるかが非常に重要である.
#3 Self-Attention Generative Adversarial Networks
※この記事は以下の論文を翻訳したものです.学習不足のため至らない点,意味不明な翻訳あるかと思いますが了承してください.なにもかも了承ください.
#8 Self-Attention Generative Adversarial Networks - HackMD
https://arxiv.org/abs/1805.08318
要旨
SAGANは注視駆動のGANである.従来の畳み込み層を用いたGANは低解像度の潜在因子空間の局所点から,高解像度の画像を生成しているがSAGANは,全潜在因子空間からのキューを用いて画像を生成する. さらに良い特徴として,ディスクリミネータが,画像の離れた部分の特徴が互いに一致しているかどうかを確認することが可能になる. また,ジェネレータに条件付けを設けるとGANのパフォーマンスに影響を与えることが最近の研究で判明している. この結果を利用して,GANのジェネレータにスペクトル正規化を適用し,訓練の改善を行った.
導入
DCGANは多クラスを含むデータセットの訓練において,まともな画像を生成することは難しい. 例えば,ImageNet GANのモデルでは,テクスチャで区別されるような,空や海などといった画像の生成には優れているが,ジオメトリによって区別されるような複雑な構造パターンを含むような画像生成には向いていない. これは,畳み込み演算は局所的な受容野を擁しているため,長距離依存はいくつかの畳み込み層を超えた後にのみ処理を行うことが可能になる. カーネルサイズを大きくすることで,この問題はある程度解決することが可能であるが,局所的畳み込みを利用することで得られるような計算効率や統計効率といった恩恵を失ってしまう.
SAGANでは,Self-Attentionのメカニズムを畳み込みGANに導入することで,長距離性と計算効率をともに解決した.
関連論文
GAN
Spectral Normalization
https://arxiv.org/abs/1802.05957
Attention Models
大域的な依存性を抽出するうえで,Attentionモデルは非常に重要である.
Self-Attention Genarative Adversarial Networks
従来のGANで最もよく使われている畳み込み層は局所近傍の情報を処理している.そのため,長距離依存性をモデル化する上で,計算機の性能などの面からでも不向きであるモデルといえる.
https://arxiv.org/abs/1711.07971
そのため,上記論文の非局所的モデルを適用し,ジェネレータ,ディスクリミネータともに空間的に離れた構造関係に対して効率的に対処する.
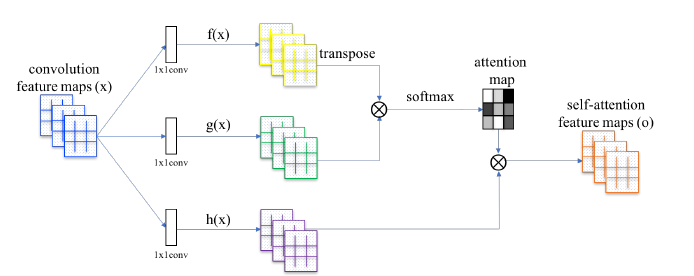
ある層に対して,そのひとつ前からの隠れ層の出力(つまり自身の入力)を$x\in \mathbb R^{C\times N}$とする.この行列に対してattentionを算出するために写像$f,g$を定める. ただし,$f(x)=W_f x,g(x)=W_g x$とする.また,$\beta_{j,i}$を以下のように定義する. これは,$j$番目の領域を合成する際にモデルが$i$番目の位置にどの程度関与するかを示す量といえる.
$$ \beta_{j,i}=\frac{\exp(s_{ij})}{\sum_{i=1}^{N}\exp(s_{ij})},\text{where}~~ s_{ij}=f(x_i)^Tg(x_j) $$
次にattention層の出力$o=\{o_1,o_2, ...,o_j,...o_N\}\in \mathbb R^N$を, $$ \displaystyle o_j=\sum^N_{i=1}\beta_{j,i}h(x_i),\text{where}~~~ h(x_i)=W_h x_i $$ と定義する.
SAGANは上記パラメータのうち,$W_g\in\mathbb R^{\bar{C}\times C},W_f\in\mathbb R^{\bar{C}\times C},W_h\in\mathbb R^{C\times C}$を$1\times 1$畳み込み層を用いて実装を行い,学習させる
この論文では$\bar{C}=C/8$として実験を行った.
最後に,アウトプットをスケーリングし,入力をつけ足したものを最終的な出力とした.すなわち,最終的な出力$y_i$は $$ y_i=\gamma o_i+x_i $$ と表せる.ただし,$\gamma$ははじめ,0で初期化を行う.すなわち,これによって学習の初めの段階は局所近傍を主に学習し,学習を重ねていくうちに漸次的に大域性を増して学習を行うことが可能になる.
損失関数は以下のものを使用する.(https://arxiv.org/abs/1705.02894) $$ \begin{eqnarray} L_D&=&-\mathbb E_{(x,y)\sim p_{data}}[\min(0,-1+D(x,y))]- \mathbb E_{z\sim p_z,y\sim p_{data}}[\min(0,-1-D(G(z),y))]\\ L_G&=&-\mathbb E{z\sim p_z,y\sim p_{data}}D(G(z),y) \end{eqnarray} $$
GAN学習安定化を支える技術
スペクトル正規化を両モデルに適用
https://arxiv.org/abs/1802.05957 の論文で提案されたスペクトル正規化はディスクリミネータにのみ適用されていたが,これをジェネレータにも同様に適用させる.スペクトル正規化は他の正規化処理と比較してハイパーパラメータチューニングを行うことがないことが大きな特徴である.
ジェネレータにスペクトル正規化を適用させることでパラメータの大きさが爆発的に増加することを抑えることが可能になり,勾配爆発の問題を避けることができるようになる.
両モデル間の学習率を不均衡にさせる
ディスクリミネータに正規化を課すと,GANの学習過程が遅れてしまうということが従来の研究により分かっている.実際,ジェネレータの1回の更新の間にディスクリミネータは数回(5回あたりが多い)の更新を行うという実装をしているものが多く見受けられる.
https://arxiv.org/abs/1706.08500
この方法とは別に,上記論文にて,ジェネレータとディスクリミネータにそれぞれ別の学習率を使用することを提案している. 数度のディスクリミネータの更新がいらなくなるため,同一時間に行える学習回数の向上が見受けれられる.
通読 #2 Improved Training of Wasserstein GANs
数式の調子が悪い.
https://arxiv.org/abs/1704.00028
要旨
GANは強力な生成モデルだが,学習が不安定という弱点がある.Wasserstein GANを用いることで,学習にある程度の安定性を持たせたが,特定のダメなサンプルのみを生成してしまうことや,収束の失敗が起こることがある.これは,ディスクリミネータ(critic)に対し,リプシッツ連続の制約を満たすべく,重みのクリッピングを行っていたことに起因することが分かった.そこで,重みをクリップするのではなく,入力に対するディスクリミネータの勾配のノルムをペナルティ項として加算するという新規手法を提案した.この方法により,従来のWGANよりも学習が安定化し,様々な種類のGANに対して,さほどハイパーパラメータチューニングを施すことなく,安定して学習できることを可能にした.
前提知識
Wasserstein GAN
https://arxiv.org/abs/1701.07875 上記論文にて,GANが最小にする発散は,ジェネレータのパラメータに対して連続でない可能性がある. そこで,上論文はEarth-Mover距離(Wasserstein距離)$W(q,p)$を使用した.これは分布$q$に従って散らばった堆積物を分布$p$に移動させる最小輸送重量コストとして定義される.軽い仮定の下では,$W(q,p)$は任意点で連続で,ほとんど至る所で微分可能である. WGANの損失関数は Kantorovich-Rubinstein双対性 を用いることで以下の式のように定義できる.

ただし$\mathcal D$は1-リプシッツ関数の集合であり,$\mathbb P_g$は$\tilde{\bf x}=G(z),z\sim p(z)$によって暗黙に定義されるモデル分布である.このような場合,最適なディスクリミネータ(この論文中では,分類を学習するわけではないのでcriticと呼んでいる)の下では,ジェネレータのパラメータの関数を最小化させることは,$W(\mathbb P_r,\mathbb P_g)$を最小化させることに等しい.
WGANの損失関数は,その入力に対する勾配がGANのそれよりも良い挙動を示すようなCritic関数をもたらすことができる.経験的に,WGANの損失関数はサンプルの質と相関関係があることが分かっている.この傾向は従来のGANには見られなかった性質である.
WGANでは,Criticがリプシッツ制約を満たすべくコンパクト空間$[-c,c]$に落とし込むようにCriticの重みをクリッピングする.この制約を満たす関数の集合は,$c$とCriticのアーキテクチャに依存する$k$に対する$k-$リプシッツ関数の部分集合である.しかしながら,この重みのクリッピングはいくつかの問題があることが知られている.
最適化Criticアーキテクチャの特性

系.1 $f^*$は$\mathbb P_r,\mathbb P_g$のほとんど至る所で勾配のノルムが$1$である.
重み制約の困難性
WGANの重みのクリッピングが,最適化を難しくし,かりに最適化がうまくいったとしても病的な表面を持ってしまうことが明らかとなっている.以下にその立証を示すが,この現象は常に起こるわけではない.
重みクリッピングのほかに,L2ノルムクリッピングや,L1,L2ウェイト減衰を用いて実験を行ったところ,同様の問題が観測された.
バッチ正規化により,これらの問題はある程度緩和されるが,かなりの深層WGANモデルにおいては収束ができないといった問題が観測されている.
不十分な能力
重みのクリッピングを使用した$k-$リプシッツ制約の実装はCriticが非常に簡単な関数へと偏らせてしまう.系1で述べたように,最適なWGANのCriticは$\mathbb P_r,\mathbb P_g$のほとんど至る所で勾配のノルムが1である.重みのクリッピング下では,最大勾配ノルムが$k$を達成しようとするNNアーキテクチャが非常に単純な関数を学習してしまうことが観察される.
勾配の爆発と消失
WGANは損失関数と重みの制約の相互作用により最適化が困難であることが観測された.結果として,ハイパーパラメータであるクリッピング閾値$c$を綿密に調整しないと勾配が消失もしくは爆発してよい学習が行えなくなる.
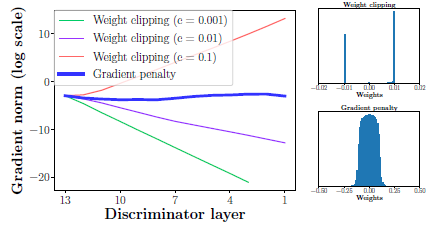
簡単なモデルにおいてこれを示すと,SwissRollデータセットに対して$c$を変えて,勾配のノルムを記録したところ,指数的に重みの爆発もしくは減衰が起きていることが判明した.なお,ジェネレータもクリティックも12層のMLPでバッチ正規化は用いていない.
勾配ペナルティ項

そこで,リプシッツ制約を満たすべく,重みのクリッピングではない別の方法を提示する. 微分可能な関数は任意点で1以下のノルムである勾配を持つ場合に限り,1-リプシッツであるといえる.したがって,入力に対するクリティックの出力勾配ノルムを直接制限することを検討する. 実装容易性の観点から損失関数に勾配ノルムに対する罰則項を設けて緩い制約を課すことを考える. ランダムなサンプル$\hat{\bf x}\sim\mathbb P_{\hat{\bf x}}$に対して,新たに損失関数を以下のように定義する.

サンプリング分布
$\mathbb P_{\hat{\bf{x}}}$を,データ分布$\mathbb P_r$とジェネレータ分布$\mathbb P_g$からサンプリングされた点間を結ぶ直線に沿って暗に定義している.この方法の裏付けとしては,最適化されたクリティックが,命題1からもわかるように,$\mathbb P_r$および,$\mathbb P_g$からの結合点を接続する勾配ノルム1を有する直線を含むという事実である.任意点で単位勾配ノルムを課すことは難しいため,これらの直線上でのみ強制させている.実験的にも,この制約により十分に良い結果が得られることが分かった.
罰則係数
すべての実験において$\lambda = 10$としている.単純なモデルから複雑なモデルまで,様々なモデルにおいて,この値が最も良いふるまいを示したため,この値としている.
クリティックアーキテクチャにバッチ正規化を課さない
バッチ正規化は入力バッチ全体を出力バッチへと写像する.そのため,単一の入力を単一の出力に射影するディスクリミネータの問題形式を変更してしまうといえる.バッチ全体ではなく個別入力に対してクリティックの勾配ノルムに罰則を課すため,バッチ正規化の下では,勾配罰則を科す目的がもはや有効ではなくなってしまう.バッチ正規化ではない,サンプル間の相関に従属しない正規化では,この方法においてはうまく動作し,特に,レイヤ正規化を課すことを推奨する.
レイヤ正規化:https://arxiv.org/abs/1607.06450
両面的罰則
勾配ノルムは1以下にさせるよりも,1に向かわせるように調整するようにさせるとよい.これは,最適なWGANでは,$\mathbb P_r$,$\mathbb P_g$下のほとんど至る所で,また,その分布間の大部分で勾配ノルムが1となるため,片面的罰則では制約が足りないであろうという経験的な推測によるものである.
実装
モード崩壊してるような…
精読 #1 An Introduction to Image Synthesis with Generative Adversarial Nets
https://arxiv.org/abs/1803.04469
要旨
GANはここ数年CVやNLP分野で劇的な進化を遂げている.特に画像合成は最も研究されている分野の一つである. この論文では,画像合成に使われる手法の分類,GANと異なるtext2imageやimage2imageのモデルとの比較,及びGANを用いた画像合成における評価指標と将来の研究の方向性について議論する.
導入
- GANの良いチュートリアル:https://arxiv.org/pdf/1701.00160.pdf
- この論文では画像合成についてのGANについて議論するが他の分野については以下の論文を参照:
- 欠落画像の補完
- 画像のキャプションの生成
- 物体検出
- セマンティックセグメンテーション
- テキスト生成
- https://arxiv.org/abs/1705.10929
- https://arxiv.org/abs/1709.08624
- 対話生成
- Q&A
- 機械翻訳
- GANをNLPのタスクで使うのは難しく,テクニックを要する https://arxiv.org/abs/1609.05473
GANの基礎
- 生成器モデル $G$
GANの生成器はノイズ$\textbf{z}$を入力とし,$G(\textbf{z};\theta)$を出力とする.出力の分布$p_g$を訓練画像の分布 $p_{data}$ を推定すべく,パラメータ $\theta$を学習する.
- 弁別器モデル$D$
訓練画像,もしくは生成された画像を入力とし,その画像が訓練画像か生成された画像かを見分けるように学習を行う.
初期のGANは全結合層を使用し,モデルを形成していたが,後のDCGANではCNNを使用することでより良いパフォーマンスを得た.
GANはよく生成器と弁別器のいたちごっこに擬えられる. すなわち,生成器が弁別器を欺くようなリアルなデータを生成し,弁別器は真偽をよりよい精度で見分けられるように双方学習を行い,高精度の画像を生成するように学習していく.

しかしながら,弁別器が生成器より学習が進んでしまうと弁別器は生成器からのサンプルを無視し,$\log{(1-D(G(\textbf{z})))}$の誤差が飽和し,生成器は勾配が0に近くなるため,何も学べなくなる. このことを防ぐため,生成器の学習の際,$\log{(1-D(G(\textbf{z})))}$を最小化するのではなく,$\log{D(G(\textbf{z}))}$を最大化する様にする.
Conditional GAN
従来のGANでは,生成される画像の種類は,入力ノイズ$\textbf{z}$にのみ依存し明示的にコントロールすることはできない. https://arxiv.org/abs/1411.1784 そこで条件付きの入力$\textbf{c}$を追加した生成器$G(\textbf c,\textbf z)$を用いて画像の生成を行う. $\textbf c$は通常,$\textbf z$に連結されて通常のGANのように生成される.また,$\textbf{c~z}$でデータオーギュメンテーションを行える.
https://arxiv.org/abs/1612.03242 $\textbf c$の目的としてはその任意性を利用して画像ならば物体の特性やテキストの説明を挿入するなどを行い生成したい画像を生成できるように誘導することを意図とする.
GAN with Auxiliary Classifier
副次的情報をより多く得るように,また,半教師あり学習を行えるようにするために追加のタスクに固有の弁別器の補助分類器を追加する.
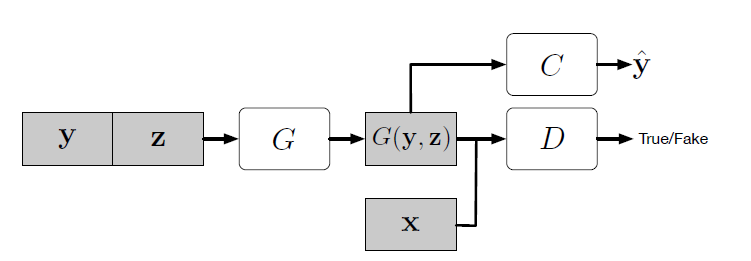
上図の$C$が補助分類器にあたり,補助分類器を追加することで,事前学習済みのモデルを使用することが可能になる. https://arxiv.org/abs/1610.09585 上記の論文でAC-GANによる画像生成は鮮明な画像を作ることを可能にしたことのほかにGANの問題の一つであるMode Collapse問題を軽減できるということが立証されている.また,このモデルは画像合成においても有用的でもある.
GAN with Encoder
従来のGANはノイズ符号$\textbf z$から合成画像$G(\textbf z)$への変換は可能であるが,その逆操作は行うことができない.ノイズ分布がデータサンプルの潜在因子空間として振舞うとしたら,GANはデータから潜在因子への写像入力能力を欠如しているといえる.
BiGAN: https://arxiv.org/abs/1605.09782
ALI: https://arxiv.org/abs/1606.00704
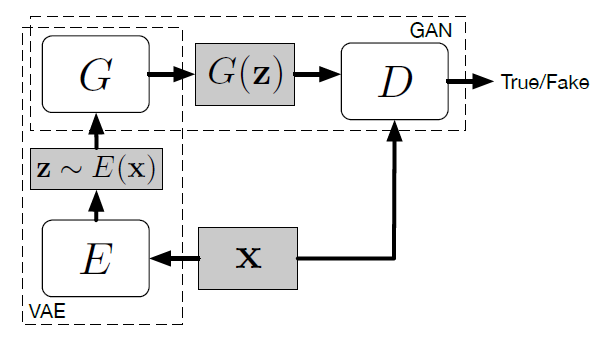
上記の2つの論文にて提案されている手法として,従来のGANの型に新たにエンコーダ$E$を追加するものがある.
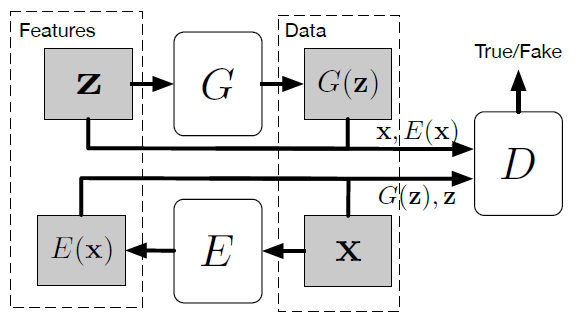
上図において弁別器$D$はノイズから生成された画像と実在の画像のほか,潜在因子ベクトルも受け取るように修正する.誤差関数は以下のように定義される.

GAN with Variational Auto-Encoder
https://arxiv.org/abs/1512.09300?context=cs
VAE-GANは変分オートエンコーダとGANの双方の良い特徴をいいとこどりすることが目的である.GANはシャープな画像を生成できるがMode Collapse等の問題があり,VAEはブラーのかかった画像だが多様な画像を生成することできる.VAE部分は標準正規事前分布を科すことでエンコーダ$E$を正規化する. VAEの損失は以下のように定義される

さらに,VAE-GANは弁別器$D$に関してVAEの再構成損失を表すことを提案している. $D_l(\textbf x)$を$l$番目の層の表現とすると,ガウス観測モデルは以下のように定義される.

これを用いると,VAEの誤差は以下のように表すこともできる.

GANの誤差は従来のGANと同じものを採用している. 実験の結果,VAE-GANは単体のVAE,GANより,良い画像を生成されることが立証されている.
Mode Collapseの対処方法
GANは画像合成に非常に効果的だが,訓練過程は非常に不安定で,良い結果を得るためには多くのコツを要領よく用いる必要がある.
https://arxiv.org/abs/1406.2661
https://arxiv.org/abs/1511.06434
https://arxiv.org/abs/1506.05751
GANはさらに上記の論文で議論されている通り,Mode Collapse(モード崩壊)問題を抱えている.
従来のGANの方法では,弁別器はさまざまな種類のサンプルを考慮せずに,ただ,入力サンプルが本物か否かのみを出力する.そのため生成器が弁別器をうまくだます少量のサンプルを生成するためだけに学習を費やす危険性がある.
MNISTの例で言うなれば,0-9の画像が含まれているのにもかかわらず,極端な場合にはうち1つの数字のみを完璧に欺くように学習し,他の9つの数字を学習しないようになってしまう.これはクラス間モード崩壊の一例である.対して,ある数字の筆記方法の差異から生じるモード崩壊は内クラスモード崩壊と言われている.
https://arxiv.org/abs/1606.03498
モード崩壊を防ぐためのアプローチは多数挙げられている.そのうちの1つとして,ミニバッチ特徴量(Minibatch Features)と呼ばれるものがある.そのアイデアは弁別器に本物の画像のミニバッチと生成された画像のミニバッチとを比較させるというアイデアである.この方法を採用すると,弁別器は生成画像が他の生成画像と比較して,潜在因子空間的に近傍に位置しているかどうかを学習することができる.
https://arxiv.org/abs/1701.00160[再掲]
しかしながら,この操作がうまくいくかどうかは,距離計測のために使用する特徴量に大きく依存しているといわれている. MRGAN,BiGANではデータ空間を潜在因子空間へ射影するエンコーダを導入してこの問題の解決を試みている.エンコーダと生成器の組み合わせはオートエンコーダのように振舞い,再構成誤差がモード正則化として,敵対的損失に加算される.すなわち,弁別器は再構成されたサンプルを識別するように訓練され,また別のモード正則化器として機能するようになる.
https://arxiv.org/abs/1701.07875
WGAN(Wasserstein GAN)はWasserstein距離を実データ分布と学習データ分布間の類似性を測る測度として使用する.(従来のGANではJensen-Shannonダイバージェンスを使っている)この方法は理論的には,収束時間が従来のGANと比較して長くなっている.
https://arxiv.org/abs/1704.00028
上記の問題を軽減するために提案された手法がWGAN-GPである.この方法ではWGANで行っていたウェイトクリッピングによる制約の代わりに勾配に応じたペナルティ項を使用している.WGAN-GPは良い画像を生成し,モード崩壊をうまく回避しておりさらに,他のGANのフレームワークに足すことが容易な方法である.
GANによる画像合成の一般的アプローチ
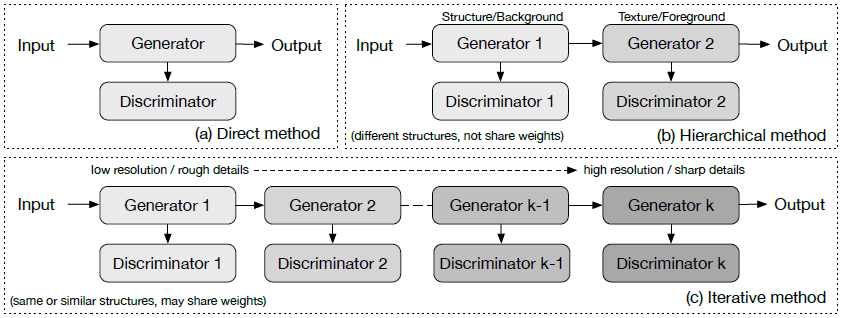
ここでは,画像生成のためのアプローチに応じて,画像生成におけるGANを次の3つの種類に分類する.
- 直接法(Direct Method)
- 階層法(Hierarchical Method)
- 反復法(Iterative Method)
直接法
1つの生成器と1つの弁別器のみを使用するモデル.どちらも,枝分かれも双方向性もない構造であり,初期のモデルの多くがこれに該当する.
- GAN
- DCGAN
- ImprovedGAN
- InfoGAN
- f-GAN
- GAN-INT-CLS
階層法
2つの生成器と2つの弁別器を使用するモデル.2つに隔てる目的としては,画像生成過程を「スタイルと構造」や「前景と背景」といった2つの構造に分け隔てることである.
https://arxiv.org/abs/1603.05631
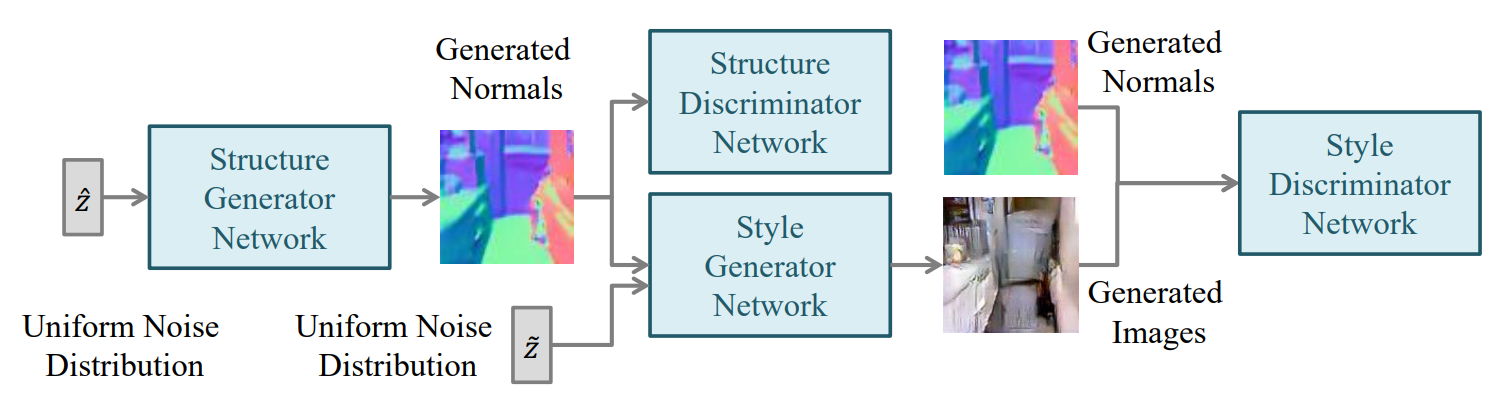
SS-GANは2つのGANを使用するモデルの一例である. まず,Structure生成器にてランダムノイズ$\hat{\textbf z}$を入力として,法線マップを生成する.生成された法線マップはStructure弁別器で真偽を判別する.Style生成器には法線画像とまた,ランダムノイズ$\textbf z$を入力とし,RGBの画像を出力する.最後に,Style弁別器にて,ノーマルマップと生成画像を入力とし,また,真偽を判別する.Structure生成器は,DCGANと同様な構造をしているが,Style生成器は少し異なっている.
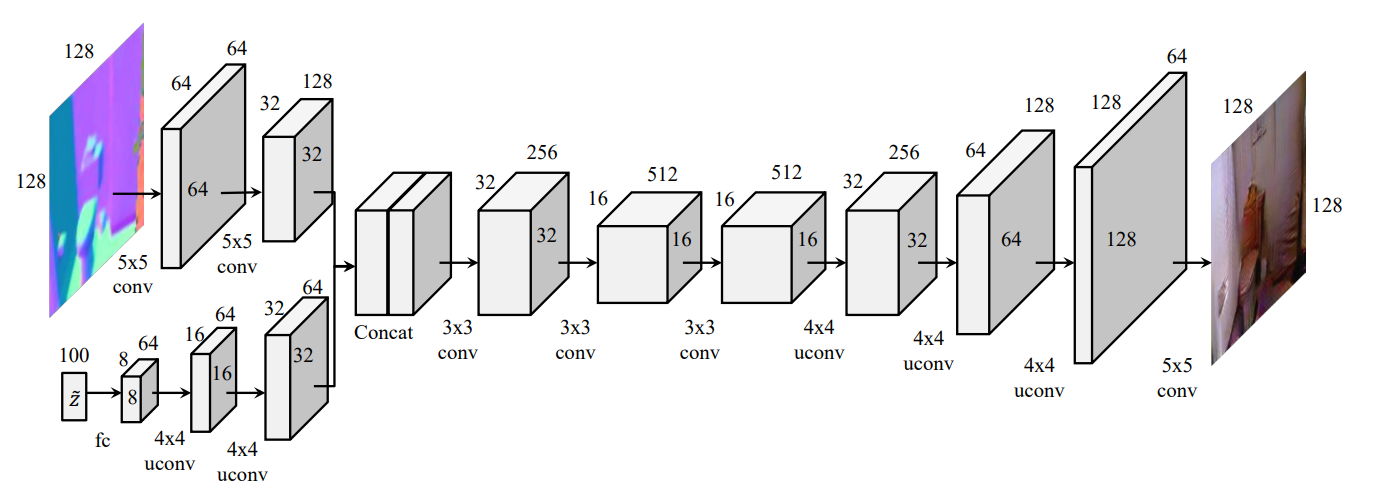
法線画像を何度か畳み込みレイヤに通し,また,ノイズを逆畳み込み層に通すなどを行い同一の縦横の長さにし2つのレイヤをチャンネル次元で連結させる.その画像をまた畳み込み層に通して,画像を新たに生成する. Style弁別器では,法線画像とそれに対応する画像をチャンネル次元で結合した画像を単一の入力として扱う.SS-GANは良質な画像を再構成するためには,良質な法線マップ情報が必要だろうという仮定の下,画像を法線マップへと射影させ,ピクセルごとに強制的に再構成法線情報を実際の画像を推定するためにピクセル単位の誤差を計算する. SS-GANの主な制約としては,画像の本当の法線情報を得るために,Kinectを使用する必要があるということである.
反復法
この方法と階層法との主な違いは,構造の似通った,もしくは全く同じな生成器をより鮮明な画像を生成するためにいくつも使用することに加え,生成器間にて重みの共有を行うという点である.
LAPGAN
https://arxiv.org/abs/1506.05751
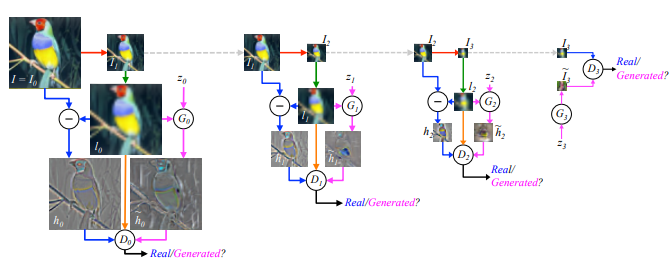
(1) $I_0$(オリジナルイメージ)を半分の大きさにダウンサンプリングし,$I_1$をつくる(赤線). (2)$I_1$を2倍でアップサンプリングし,$l_0$をつくる(緑線). (3)等確率で青線もしくはピンク線の処理を行う. (4)-A 青線の場合は$h_0=I_0-l_0$でハイパスを計算し,$D_0$は$h_0$と$l_0$を受け取り真偽を評価する (4)-B ピンク線の場合は$G_0$が$l_0$とノイズ$z_0$を受け取り,ハイパス画像を生成する.(4)-A同様$D_0$にて真偽を評価する (5)再帰的に(1)-(4)を繰り返していきある程度の大きさになったら通常のGANと同様の構造で画像生成を行う. (原著論文より訳して引用)
LAPGANは反復的な方法を始めて用いたGANのモデルである.LAPGANでは,ラプラシアンピラミッドを利用することで,鮮明な画像を生成しようと試みている. LAPGAN内の生成器はすべて前の生成器から生成されたデータとノイズを入力とし,ラプラシアンフィルタを施した画像の生成を行う.
StackGAN
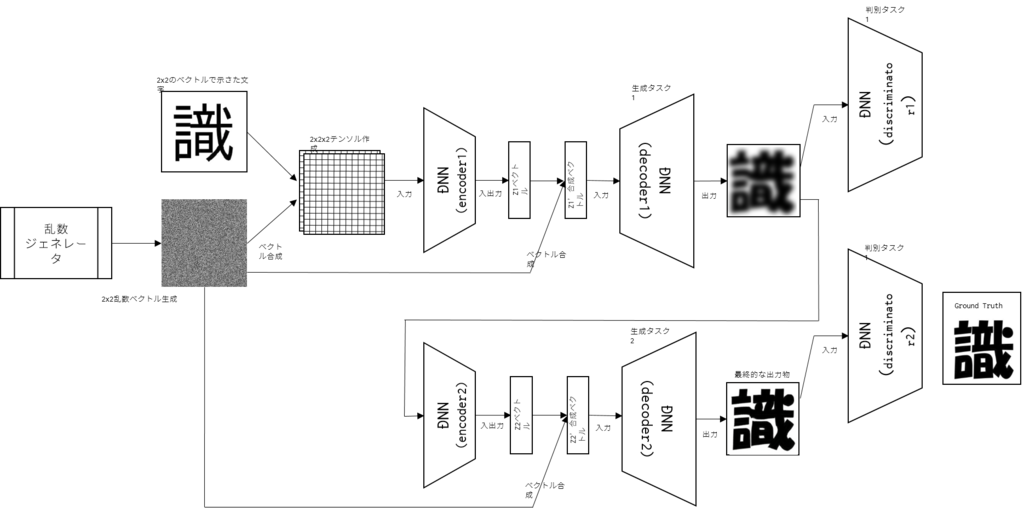
https://arxiv.org/abs/1612.03242
StackGANは反復法の一つだが生成器は2つしか存在しない. 1つ目の生成器にて$(\textbf z,\textbf c)$を受け取り,ブラーのかかった荒い画像を生成する. 2つ目の生成器では$(\textbf z,\textbf c)$と1つ目の生成器で作られた画像を入力として,より鮮明な画像を生成する.
SGAN
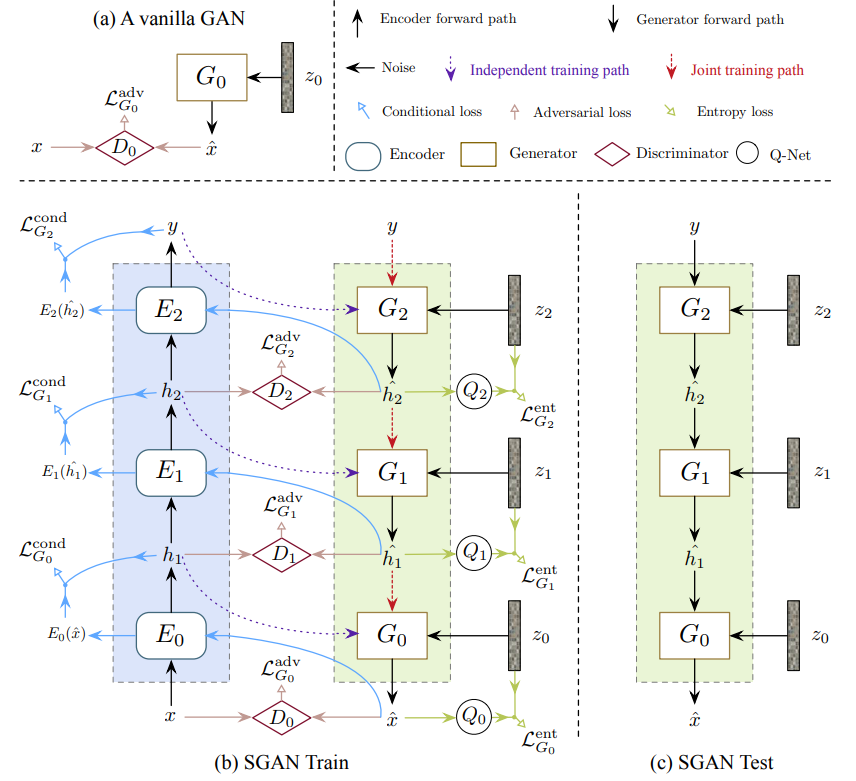
https://arxiv.org/abs/1612.04357
SGANは生成器を幾重にも積み,低レベルの潜在因子空間をより高レベルの潜在因子空間へと写像することを繰り返して鮮明な画像を生成する. さまざまな特徴量空間に別々の生成器を使用する意図としては,SGANがエンコーダ,弁別器,およびQ-ネットワーク(エントロピー最大化を行うための事後確率$P(\textbf z_i|\textbf h_i)$予測のために使用されるもの)を各生成器に関連付けして,それらの機能改善を図るためである.
その他
Progressive GAN
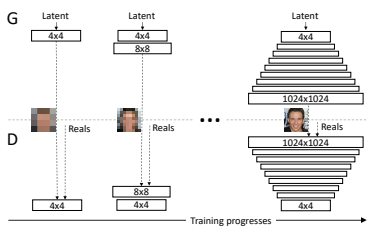
https://arxiv.org/abs/1710.10196
Progressive GANでは,はじめ$4\times4$で生成と弁別を行い,学習を行った後,倍解像度の画像を生成させる層を追加し,再度学習を行う.この操作を繰り返し,$1024\times 1024$の画像においてもかなり鮮明に画像を生成することができる.
日記(5/12-5/13)
レポートのせいで土日が潰れた.おわり.
5/11に書いたQ学習合ってるか自信無いから強い人に見て欲しい~
日記(5/11)
5/11
Coursera
強化学習に関しては全く未知よりの未知*1だったので学ぶことが多く新鮮.
環境構築ついでに興味のあったQ学習について調べてみた.
Q学習
以下,「車が坂を登る」ために人工知能が各時間にどのような行動を取ればよいかという問題を考える.

車は各フレームに右進,静止,左進のいずれかの行動を取ることができるものとする.

Q学習では,環境とエージェントというものを考える.エージェントは環境に応じて行動を起こす.また,エージェントはその行動と環境の情報からその行動の価値を出力する行動価値関数というものを持っており,エージェントは基本,この行動価値関数が最大であるような行動を取る.行動の価値は,環境からの報酬によって得られこの報酬を用いて更新される.
この行動⇨環境の変化⇨報酬⇨更新のプロセスを繰り返し,よりよい行動価値関数を得ることがQ学習の目的である.
この坂上りにおいて,環境は車の位置と速さであり,行動は前述のように右進,静止,左進であり,報酬はステップごとに-1である.また,位置と速さは離散値として扱いたいため最大値と最小値の間を40分割する.
以降の図において静止:0,左進:1,右進:2とする.
注:報酬情報を勘違いしていたので以降の図の報酬情報:0は間違いで-1が正しい(かも)

エージェントは(位置×速さ×行動)の3次元の配列に行動価値を保存する行動価値関数(Qテーブル)と,行動情報,環境情報,報酬情報を保持しているとする.まず,現在状態の位置,及び速さにおけるQテーブルを参照にし,取るべき行動を取得する.

取るべき行動に応じた環境からの応答は次フレームにおける位置,速さ,及び報酬である.

これらの行動によって得られた環境と報酬,及び行動前の環境の情報を用いてQテーブルの更新を行う.
Qテーブルの更新は移動前の環境情報を$s_0$,移動後を$s_1$とし,行動を$a$,報酬を$r$と置くと,
$$Q \left(s_0, a\right) \longleftarrow Q \left(s_0, a\right)+\alpha\left(r+\gamma\max_{a’}~{Q\left(s_1, a'\right)}- Q \left(s_0, a\right) \right)$$
のようにして更新される.
ただし,$\alpha$は学習率と呼ばれ,今回は$0.2$,$\gamma$は割引率と呼ばれ,今回は$0.99$とした.
このプロセスの繰り返しにより精度を高めていく.
ただし,この方法では局所解へと陥る可能性があるため,常に行動価値関数が最大の行動を取るのではなく,たまにランダムな方向へと移動するようにする.この方法のことは$\varepsilon-$グリーディ法と呼ばれる.
こちらにあるコードを参照にして実装を行った結果,20000エポックを経たあと,なんかめっちゃいい感じで坂を登っていた.すごい.
- 実験レポート
- Kaggle
- Coursera
- Ruby on Rails
- Blender
- AOJ-ICPC過去問
- 適度な運動
- 整った食習慣
- 質の良い睡眠
*1:JK流行語
日記(5/10)
5/10
Coursera
とうとう強化学習コースが開放されたのではじめて行く. 見た感じ一週間あたりたかだか3時間程度で行けるらしいので Kaggleのやつと同時並行をしていく.
実験レポート
橋梁の有限要素解析を行った. 有限要素解析自体は面白そうだけどレポートは手書きだし書きたくない.
- 実験レポート
- Kaggle
- Coursera
- Ruby on Rails
- Blender
- AOJ-ICPC過去問
- 適度な運動
- 整った食習慣
- 質の良い睡眠